
人工智能课程设计报告
人工智能课程设计报告
1.引言
随着我国经济快速发展,城市人口急剧增加,带来了一系列的社会问题。交通拥堵,环境遭到破坏,公共交通的快速发展可以有效解决人们出行和交通拥堵的问题。自行车具有机动灵活、低碳环保的优点,若自行车可以取代现在的机动车,那么道路就不会那么拥挤,人们的出行效率就会大大提升,汽车废气的排放量也将大大的减少,环境的质量也会提升。同时,为了完美的解决从地铁站到公司、从公交站到家的“最后一公里”路程,共享单车应运而生.
共享单车有效的解决了“走路累,公交挤,开车堵,打车贵”的苦恼。一夜之间,北上广深、甚至部分二线城市,共享单车大街小巷随处可见。继2016年9月26日ofo单车宣布获得滴滴快车数千万美元的战略投资,双方将在共享单车领域展开深度合作之后,摩拜单车也于2017年1月完成D轮2.15亿美元(约合人民币15亿元)的融资,国内共享单车更加火爆,最近一张手机截屏蹿红网络。在这张截图上,24个共享单车应用的图标霸满了整个手机屏幕,真的是“一图说明共享单车的激烈竞争”。而在街头,仿佛一夜之间,共享单车已经到了“泛滥”的地步,各大城市路边排满各种颜色的共享单车。共享经济的不断发展逐渐的改变着人们的日常生活,共享精神也逐渐深入人心。
1.1任务要求
要求运用人工智能相关理论和方法设计计算机系统解决实际问题。
2.详细设计
2.1 设计步骤
1.共享单车骑行数据的获取
运用python库(BeautifulSoup,requests,scrapy)对优易数据网站(http://www.youedata.com/)Kaggle和进行爬取共享单车的骑行数据。
将爬取的数据写入csv文件中:

分析数据集:
数据集来源于加利福尼亚大学欧文分校(UCI)大学的公开数据集:https://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset,本次数据集的信息参考该网站。共享单车数据集包含有两个文件,一个是按天来统计的共享单车使用量数据,另一个是按照小时数来统计的使用量。
共享单车数据集是在2011年至2012年间收集的,此处的共享单车是采用固定桩形式的单车,类似于中国的永安行,并不是我们目前所看到的满大街的小黄车,摩拜之类。
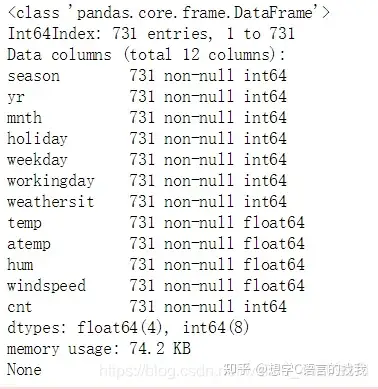
本数据集总共有17389个样本,每个样本有16列,其中,前两列是样本序号和日期,最后三列数据是不同类型的输出结果。


2.导入并理解数据
首先导入并读取查看训练数据和测试数据:



测试数据共7列,10886行,且所以数据完整,没有缺失。然后需要我们通过模型来进行预测。
导包:

3.数据处理与分析
在数据处理过程中,最好将训练数据与测试数据合并在一起进行处理,方便特征的转换。通过查看数据,确保测试数据均无缺失,或不一致。特别是在,日期时间特征由年、月、日和具体小时组成。可以根据日期计算其星期,然后就可以将日期时间拆分成年、月、日和星期5个特点。
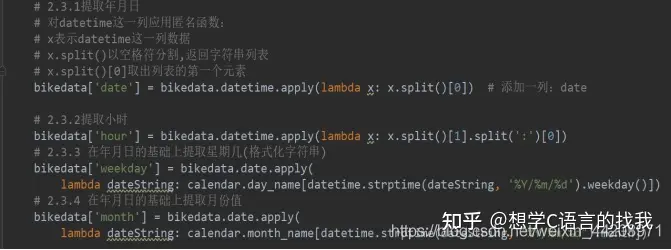
分析按天来统计的共享单车使用量数据集:

4.数据分析
规范数据后,快速查看各影响因素的结果:

从相关系数,不同月份、季节对骑行人数的影响。未来更加值观地展现所有特征之间的影响,通过绘制柱状图来实现。

接下来,深入分析各特征的影响规律,对每个特征进行可视化:


由随机森林模型预测分析:

结果说明:
Instant记录号
Dteday:日期
Season:季节(1=春天、2=夏天、3=秋天、4=冬天)
yr:年份,(0: 2011, 1:2012)
mnth:月份( 1 to 12)
hr:小时 (0 to 23) (在hour.csv有)
holiday:是否是节假日
weekday:星期中的哪天,取值为0~6 workingday:
是否工作日 1=工作日 (是否为工作日,1为工作日,0为周末或节假日 weathersit:天气(1:晴天,多云;2:雾天,阴天;3:小雪,小雨;4:大雨,大雪,大雾)
temp:气温摄氏度
atemp:体感温度
hum:湿度
windspeed:
风速
casual:非注册用户个数
registered:注册用户个数
cnt:给定日期(天)时间(每小时)总租车人数,
响应变量y (cnt = casual + registered)
1.输出结果可以看出,这个数据集中没有缺失值,且每一列的数据特征都一致的,不需要进行额外的修改
2.数据集中的season等7列是int64类型,意味着这些数据需要重新转换为独热编码格式,season中的1=spring,2=summer,3=autumn,4=winter,需改成独热编码形成的稀疏矩阵。
构建随机森林回归模型:
直接使用随机森林回归模型直接拟合

绘制不同特征的相对重要性直方图:

3.关键技术
1.导包操作:科学计算包nnumpy,pandas。可视化工具matplotlib,seaborn
Matplotlib是一个python的2d绘图库,我们可以通过这个库将数据绘制成各种2D图形(直方图、散点图,条形图等)。
2.我们做数据可视化,其实就是对数据进行分析,pandas是一个非常强大的数据分析工具包。
通常使用pandas进行下列图形的快速绘图:
1.‘line’
2.‘bar’ for bar plots
3.‘box’ for boxplot
4.‘area’ for area plots
5.‘scatter’ for scatter plots
3.NumPy(Numerical Python)是目前Python数值计算中最为重要的基础包,主要包含以下内容:
·高效多维数组ndarray,提供了基于数组的便捷算数操作以及灵活的广播功能;
·对所有数据进行快速的矩阵计算,而无需编写循环程序;
·对硬盘中数组数据进行读写的工具,并对内存映射文件进行操作;
·线性代数、随机数生成以及傅里叶变换功能;
·用于连接NumPy到C、C++和FORTRAN语言类库的C语言API。
4.Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
5.在Python中,有很多数据可视化途径。
Matplotlib非常强大,也很复杂,不易于学习。
Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,
大多数情况下使用seaborn就能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。
4.运行结果
4.1 运行环境
硬件配置:
Cpu主频2.80GHz,8GB内存
软件配置:Windows操作系统(x86),python3.6,pycharm
4.2运行结果



打印初始数据集:
直接使用随机森林回归模型结果:

不同特征的相对重要性直方图:

数据可视化分析


一周内骑行时间分析
不同月份骑行人数可视化分析
4.3 实验结果分析
1.在没有对数据集进行任何处理的情况下,采取了默认的随机森林回归模型得到的模型在测试集上的MSE很大,解释方差分和R2都是0.93,表明模拟还可以。
2.从相对重要性图中可以看出,温度对共享单车的使用有较大的影响性,从正常生活中可以理解,冬天太冷或夏天太热,骑行共享单车的人数就会显著减少。所获取的数据集是2011和2012年的,如果要得到更加可信的结果,还需要更多年份的数据。
1.可以从图表中看出秋季和冬季的骑行人数较多,可能是气候的原因,太热人们不愿意骑车出行
2.早上上班和晚上下班高峰期,骑行人数有明显的增加,反观工作时间,骑车的人数较少,上下班时段为使用共享单车的高峰。
3.非工作日中人们出行可能会更多使用汽车或其他公共交通出行,工作日中使用共享单车较多,周末时可能数量会相对减少。
1.在夏季5,6,7,8月份是全年的共享单车使用最多的时候,相比12月与1月是全年用车低峰,冬季户外太冷,共享单车使用急剧下降。
5.心得和结论
5.1结论和体会
本次人工智能课程设计完成了对共享单车数据的分析和数据可视化,从中更加直观的反映不同月份,不同时间共享单车的使用情况,以及使用随机森林回归模型反应影响共享单车使用的因子的重要性。设计中通过直方图,曲线图等图表简练地反映了共享单车的使用情况。
但由于数据集采用的年份较少,不能得到一个更加可信的参考结果,因此还需要更多年份的数据。影响共享单车使用还有地域等等客观因素,这些还没考虑周全,希望以后能完善对其的研究。
设计中遇到的问题:
1)normalize是标准化,另外你这里分别对训练和测试数据标准化是有问题的。分别处理会导致数据分布变得不一样。
2)数据特征工程做的少,类别型特征没有处理。
3)模型跑出来之后,完全没有结果的解析
主要参考文献
[1]加利福尼亚大学欧文分校(UCI)大学的公开数据集https://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset,访问日期:2019年12月.
[2]优易数据网站
http://www.youedata.com/,访问时间:2019年12月
[3]Python机器学习经典实例,Prateek Joshi著,陶俊杰,陈小莉译
[4]《Probabilistic Graphical Models-Principles and Techniques》Koller著
[5]《Introduction to Mathematical Statistics》 第六版,Hogg著
[6]Two Faces of Active Learning50, Dasgupta, 2011
[7]Active Learning Literature Survey8, Settles, 2010
[8]A Survey of Online Failure Prediction Methods2, Salfner, 2010
[9]《统计学习方法》作者李航
[10]《机器学习及其应用》 周志华、杨强主编。
[11]《数学之美》,作者吴军
[12]《Pattern Classification》(《模式分类》第二版)作者Richard O. Duda[5]、Peter E. Hart、David。
本文由某某资讯网发布,不代表某某资讯网立场,转载联系作者并注明出处:http://www.nxfun.com/index.php?m=home&c=View&a=index&aid=551
